Best-Selling Hosting
- Colocation Hosting
- Shared Hosting
- VPS Hosting
- Reseller Hosting
- Windows Hosting
- PHP Hosting
- Multiple Domain Hosting
- ASP Hosting
- Best Web Hosting Companies
- Dedicated Servers
- Java Hosting
- Managed Servers
- Coldfusion Hosting
- Linux Hosting
- Database Hosting
- > All Hosting Services
Top Rated Providers
Editors Pick
The Planet UPS Failure, no client communication
Published: Mar 31, 2005
-
Rating
4/5
Rating
4/5The Planet, www.theplanet.com, had a major problem with thier UPS systems feeding part of their datacentre, causing a large section of the network to go offline, including all staff PCs and their own websites.
The Planet UPS Failure, no client communication
The Planet, www.theplanet.com, had a major problem with thier UPS systems feeding part of their datacentre, causing a large section of the network to go offline, including all staff PCs and their own websites. During this downtime they did not communicate with their clients until hours passed, even then they barely told us anything, as we found being a customer of The Planet.
The downtime was estimated at 6 hours for many clients, some longer. Phase 2 of the D2 data center was mainly affected and a very sporadic small amount of servers were affected at D4 purely due to routing issues through D2. D5 has shown no down time due to this problem.
With hundreds of furious customers frantic of not knowing what was happening, because ThePlanet.com, ServerMatrix.com and all their other sites including the client area, Orbit, were all offline, a massive thread starting to apprear on WebHostingTalk.com http://www.webhostingtalk.com/showthread.php?s=&threadid=390336
The thread has grown to a massive 93 pages at the time of this article being published.
The thread was getting a new page every few seconds! It was crazy. Someone managed to find a link to a webcam and started watching techs run around in the datacenter - somehow its strange that their webcams work, client servers and their own websites do not? Hmmmmm
Estimated 8:30AM EST an employee finally decided to make an announcement of the situation on WebHostingTalk.com, 5 hours after the initial program started being reported.
"At approximately 4:15AM CST, a pair of redundant Powerware 500KVA UPS units failed creating a power failure in section B of our DLLSTX2 datacenter. Emergency teams were deployed within minutes and power was restored within minutes but intermmittment power outages did occur until 6:45AM CST. Powerware, JT Packard, and electricians are currently onsite with over 100 Planet technicians working to resolve the issue. We do not anticipate any further outages . A formal RFO will be released once the team debriefs. We apologize for all issues that has caused."
It was laughable if anything, we watched the techs run around on the webcams and someone managed to get a few good screenshots and edit them.
Funny Techs in the DC





People that were phoning in to The Planet, the techs were saying it was a routing/switch issue and denied a power issue......
Orbit and their own sites start coming back online.
Later they posted on their Orbit area of a popup for customers.
"Description: At 4:09AM CST, a power failure occurred in a redundant pair of Powerware UPS units feeding power to section B of the DLLSTX2 datacenter. The power failure was caused by a faulty fuse in UPS unit B-1. As the load transferred to UPS unit B-2, the spike in the load created an overloaded breaker and UPS B2 also lost power. This resulted in a power outage to the main power distribution unit feeding section B of the datacenter floor. Emergency teams were notified and the power was restored within 20 minutes. The power continued to cycle until 6:45AM due to the faulty fuse and the inability of the redundant UPS units to remain in bypass mode. Customers may have noticed several power cycles during this time period. Powerware, JT Packard, and electricians found the problem and replaced the faulty hardware and fuses. At 6:45AM, all electrical service was restored to normal and the NOC team began to bring all servers back online. The technical staff is currently placing a console on all servers to verify server restarts. Customers with operating systems that require a file check may have experienced extended downtime during the file check. Powerware and JT Packard will continue to monitor the UPS systems for the next 24 to 48 hours. The Planet does not anticipate any further outages. "
Finally when Orbit came back online I put in a reboot request for my server and received this message shortly after:
"At approx. 4:15 AM CST, a pair of redundant Powerware 500KVA UPS units failed - creating a power failure in Section B of our D2 datacenter. Emergency teams were deployed within minutes and power was restored, however intermittent power outages have continued to occur until 6:45 AM CST. Powerware, JT Packard, and electricians are currently onsite with over 100 Planet technicians working to resolve the issue. We do NOT anticipate any futher outages. A formal RFO will be released once the team debriefs. We apologize for all the issues this has caused you.
We will be performing a sweep of the data center as soon as this issue is completely resolved to reboot and ensure connectivity of all Active servers. "
Orbit Goes Offline....
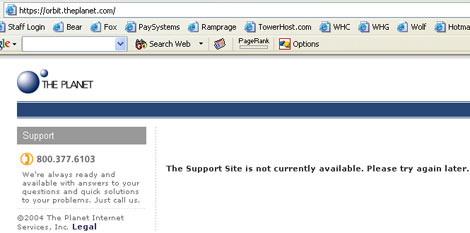
My server finally goes back online, as do many others as the techs manually reboot each machine.
Later during the day at about 2:30 PM EST they posted this on the Server Matrix forums (http://forums.servermatrix.com)
"Once this issue arose, our priority was to bring up all border routers and routing devices. This power failure affected our office connectivity via PC hence the reason there were no post on our forums or on WHT. We also called in all resources from other locations (including home) to aid in the re-lighting of D2 part 2. We were not intentionally leaving our beloved customer in the dark, but we didn’t really have a quick fix to make an official announcement. I noticed in some post that it say’s “we could have taken 30-60 seconds to post and advise of the situation” but in reality it would have required someone to leave D2 and travel to another location just to place a post on a web site when in that same amount of time we could have had yours and 23 other servers on the same rack up and running.
We were in the middle of a major failure and the priority was to regain connectivity and get our customers and our portal online and then offer an explanation and for anyone that bothered to call our phone was also a priority. The last thing anyone wants is for you hosting company to blip off the map and then when you call, no one answers the phone. That’s when you start shaking in your boots. That’s when you should worry.
I must remind everyone that yes this is the internet and data moves at lightning speed but hardware is hardware is hardware and will always be hardware. One fact of life is that hardware fails and as we have proved today, when it does, the planet and it’s employees are dedicated to getting everything back up and functional. Even Mr.Smith was on the data center floor rebooting servers and answering tech support calls since 6am! "
Lesson to be learned, don't put all your websites in one basket, have a backup solution and don't rely on your datacenter for communication.
If we find any more updates on this, this article will be updated.
Related Articles
- ResellersPanel.com Launches Private DNS Cluster Packages
- Hostingcon Announces Three Keynote Speakers
- Web Hosting Company Voxtreme acquires rival - HTTPme
- Updated kernel packages resolve security vulnerabilities
- HostVoice.net Launches '$20 CashBack' Promotion
- Hosting company reveals hacks, citing disclosure law
- Advisory: cPanel can list all users accounts
- Server Matrix/The Planet experience network downtime
- PRIMUS Telecommunications Named to the Fortune 1000
- HostingCon 2004 pre-registration now available
- Stop using sub-domains, or cough up
Comments (0)
No one has commented on this page yet.
Add Your Thoughts
WebHostGear.com is a hosting directory, not a web host.
Copyright © 1998-2024 WebHostGear.com